11. Modelos
La sección de Modelos permite gestionar los modelos de inteligencia artificial disponibles en LUCA, incluyendo modelos públicos de proveedores externos, modelos privados personalizados y despliegues.
Al acceder aparecen, en la parte izquierda de la ventana, las pestañas Público, Privado y Despliegues. La pestaña Público aparece preseleccionada.
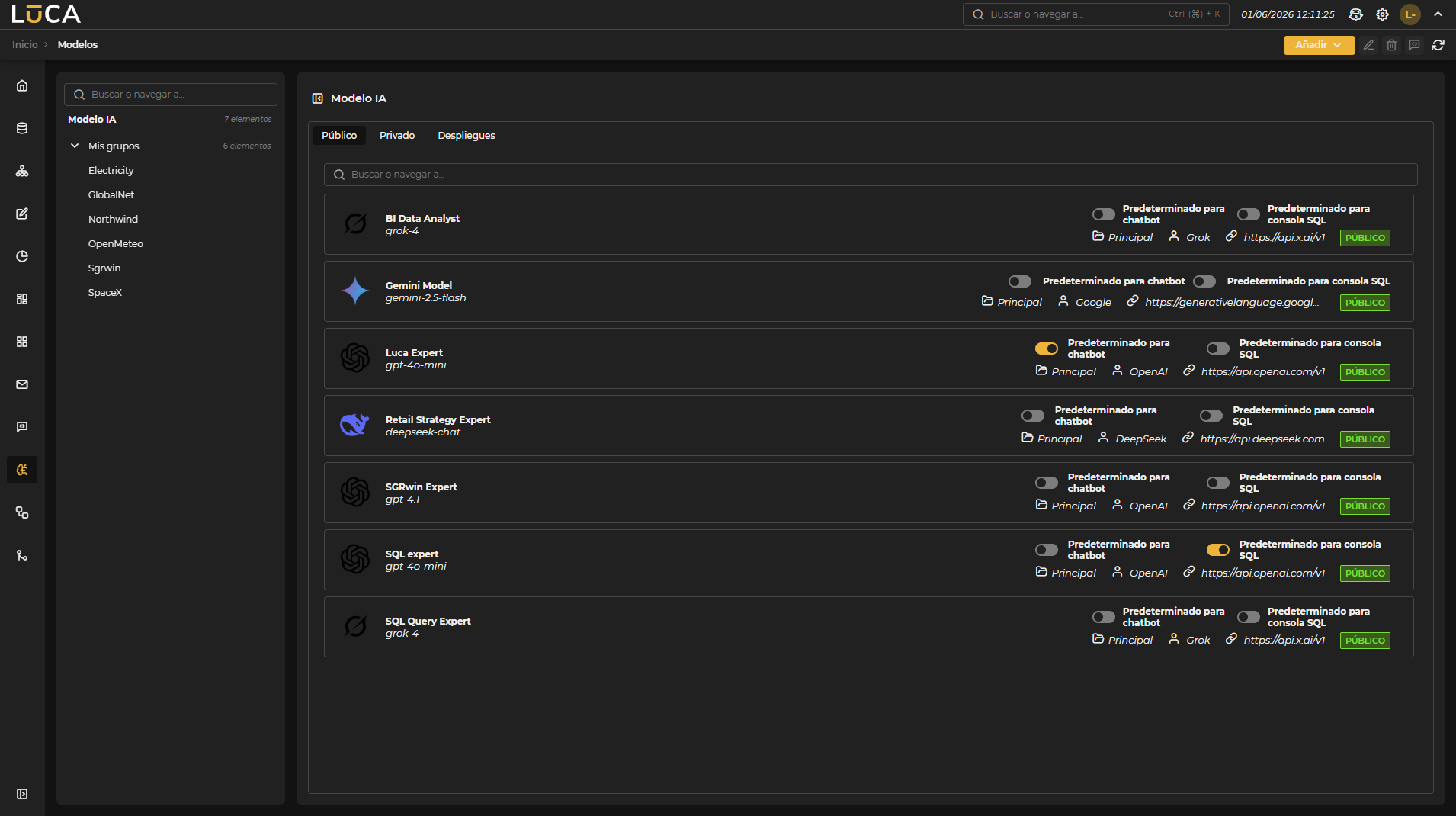 Figura 11.1: Ventana de administración
Figura 11.1: Ventana de administración
A la izquierda aparece el organizador de grupos ya que, los modelos, como elemento de la aplicación que son, también están asociados a un grupo.
Dependiendo de la pestaña seleccionada en la pantalla de administración de modelos, se muestra la lista de modelos disponibles de cada tipo y un buscador de modelos en la parte superior.
La sección de modelos Públicos permite gestionar aquellos modelos que se alimentan de las APIs públicas de los principales proveedores.
En la pestaña Privado, la lista está formada por los modelos personalizados creados a partir de los elementos previamente desplegados en la pestaña Despliegues. Esto permite adaptar y configurar modelos específicos según las necesidades de cada grupo, aprovechando los recursos privados.
Pestañas Público, Privado y Despliegues
Sobre la lista de modelos aparecen los siguientes botones:
Figura 11.2: Botón añadir
- Añadir: Al pulsar el botón se abre una ventana de contexto que permite elegir el tipo de modelo que se quiere desplegar. Al pulsar sobre uno de ellos se carga, en el panel central, el formulario de configuración correspondiente (con pequeñas diferencias en la pestaña despliegues) que permite crear un nuevo modelo:
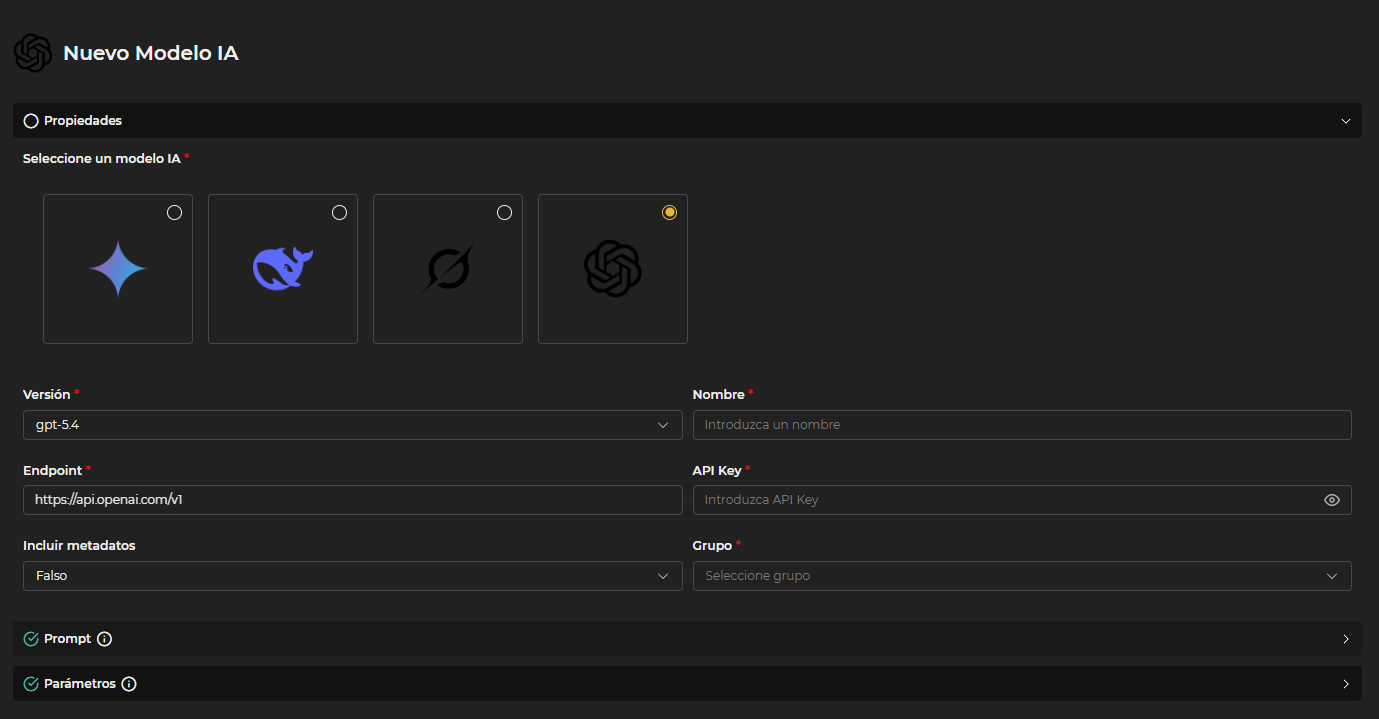 Figura 11.3: Propiedades
Figura 11.3: Propiedades
- Propiedades
- Modelo : Selecciona el modelo de la lista mediante el icono correspondiente.
- Versión : Elige la versión disponible para el modelo en el desplegable.
- Nombre : Asigna un nombre identificativo al modelo.
- Endpoint : Indica la dirección a la que se enviarán las llamadas al modelo.
- API Key : Introduce la clave configurada para el acceso al modelo.
- Incluir metadatos : Al activar esta opción, el modelo podrá acceder tanto a los datos generados durante la ejecución de las consultas SQL como a la propia consulta realizada. Esto permite ampliar el contexto disponible y mejorar el control sobre el resultado obtenido, facilitando respuestas más precisas y adaptadas a la información procesada en tiempo real. Si la opción está desactivada, el modelo únicamente recibirá el resultado final de la consulta, sin acceso a los datos intermedios ni a la consulta ejecutada.
- Grupo : Selecciona el grupo en el que se incluirá el modelo.
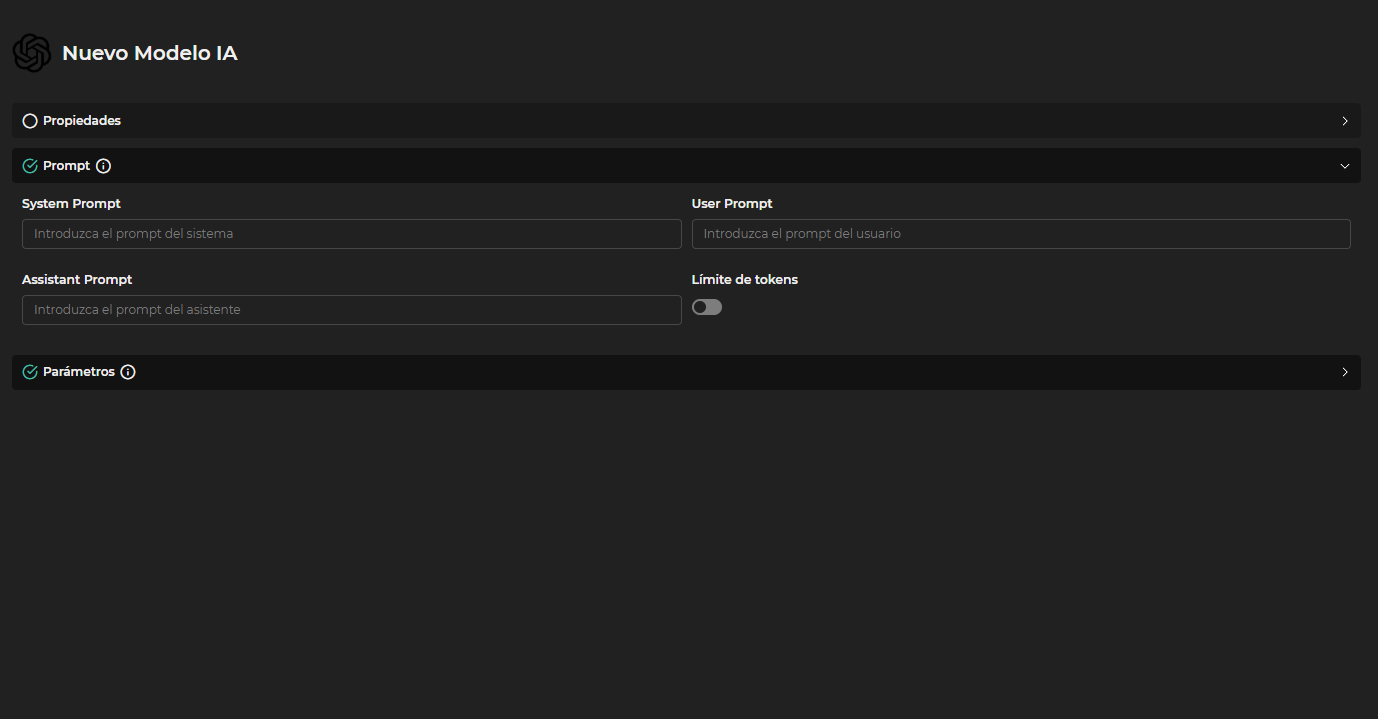 Figura 11.4: Prompt
Figura 11.4: Prompt
- Prompt
- System Prompt : Define el mensaje base que el sistema utilizará para contextualizar la interacción con el modelo.
- User Prompt : Especifica el mensaje que el usuario introduce como consulta o instrucción. Por defecto "
<|query|>". - Assistant Prompt : Indica el mensaje que el asistente (modelo) utilizará como respuesta o guía. Por defecto "
<|context|>". - Límite de tokens : Establece el número máximo de tokens que se pueden emplear por semana. Desactivado funciona sin límites.
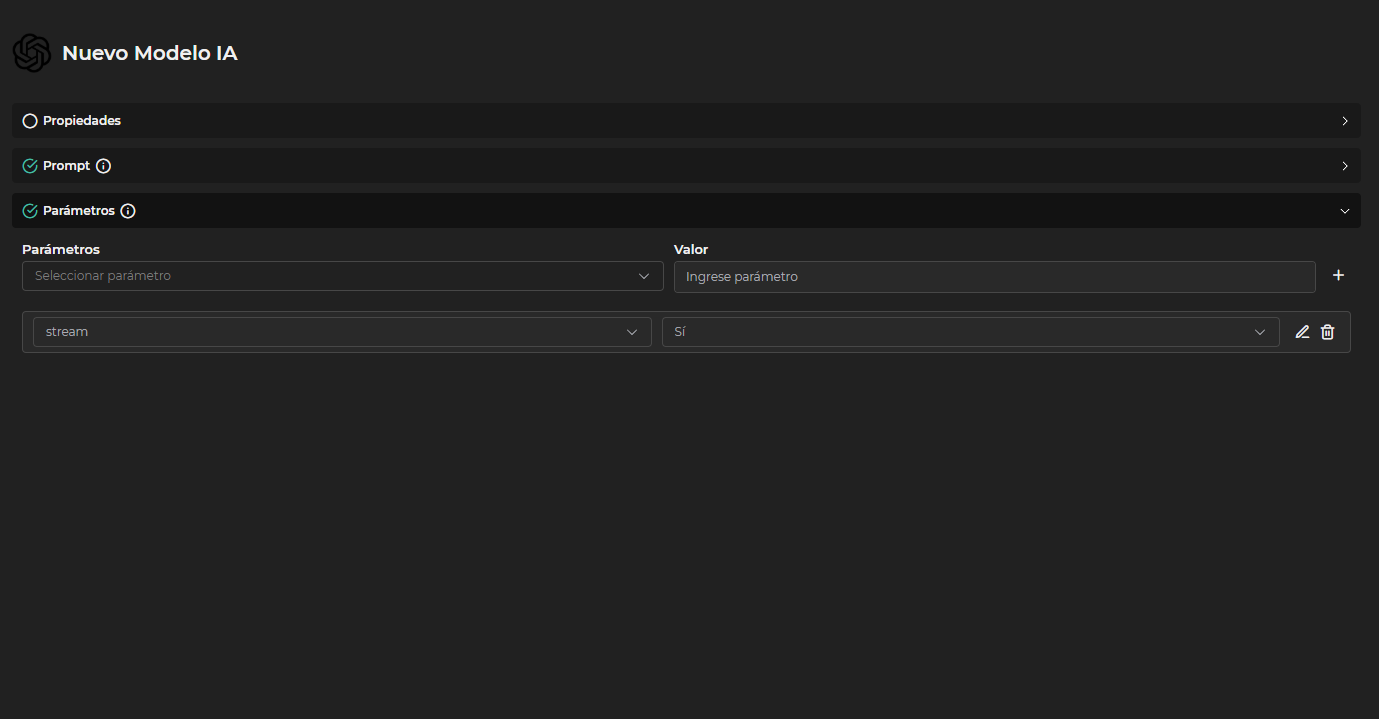 Figura 11.5: Parámetros
Figura 11.5: Parámetros
- Parámetros
- Parámetros : Selecciona un parámetro de la lista.
- Valor : Añade un valor.
- Parámetros seleccionados : Visualiza los parámetros previamente configurados
Los parámetros disponibles para la configuración del modelo son los siguientes:
- frequency_penalty: Penaliza la repetición de palabras o frases. Valores altos reducen repeticiones, valores bajos permiten más libertad.
- logit_bias: Permite favorecer o prohibir ciertos tokens (palabras). Se pasa como un mapa de identificadores de token y sus sesgos.
- logprobs: Devuelve la probabilidad logarítmica de cada token generado, útil para depuración y análisis.
- top_logprobs: Número de alternativas de tokens y sus probabilidades a devolver en cada paso, junto con
logprobs. - max_completion_tokens: Límite de tokens que puede generar la respuesta, controla la longitud máxima de la salida.
- n: Número de respuestas distintas que el modelo debe generar para la misma entrada.
- presence_penalty: Penaliza la repetición de temas ya mencionados, promoviendo mayor variedad en la respuesta.
- response_format: Define el formato de salida. Puede ser
"text","json","xml", etc. - stop: Lista de secuencias que, si aparecen, detienen la generación automáticamente.
- temperature: Controla la aleatoriedad de la respuesta. Valores bajos (
0.0) hacen la salida más determinista; valores altos (>1) la hacen más creativa o impredecible. - top_p: Alternativa a
temperature, limita las opciones a un subconjunto de tokens cuya probabilidad acumulada no supere el valor especificado.
La opción Desplegar del botón Añadir tiene un formulario particular.
En el apartado de propiedades se selecciona Modelo, Versión, Nombre para el modelo, Servidor (el cliente en el que se despliega el servidor de modelos de IA previamente configurado en Administración > Clientes), y un Grupo en el que incluirlo.
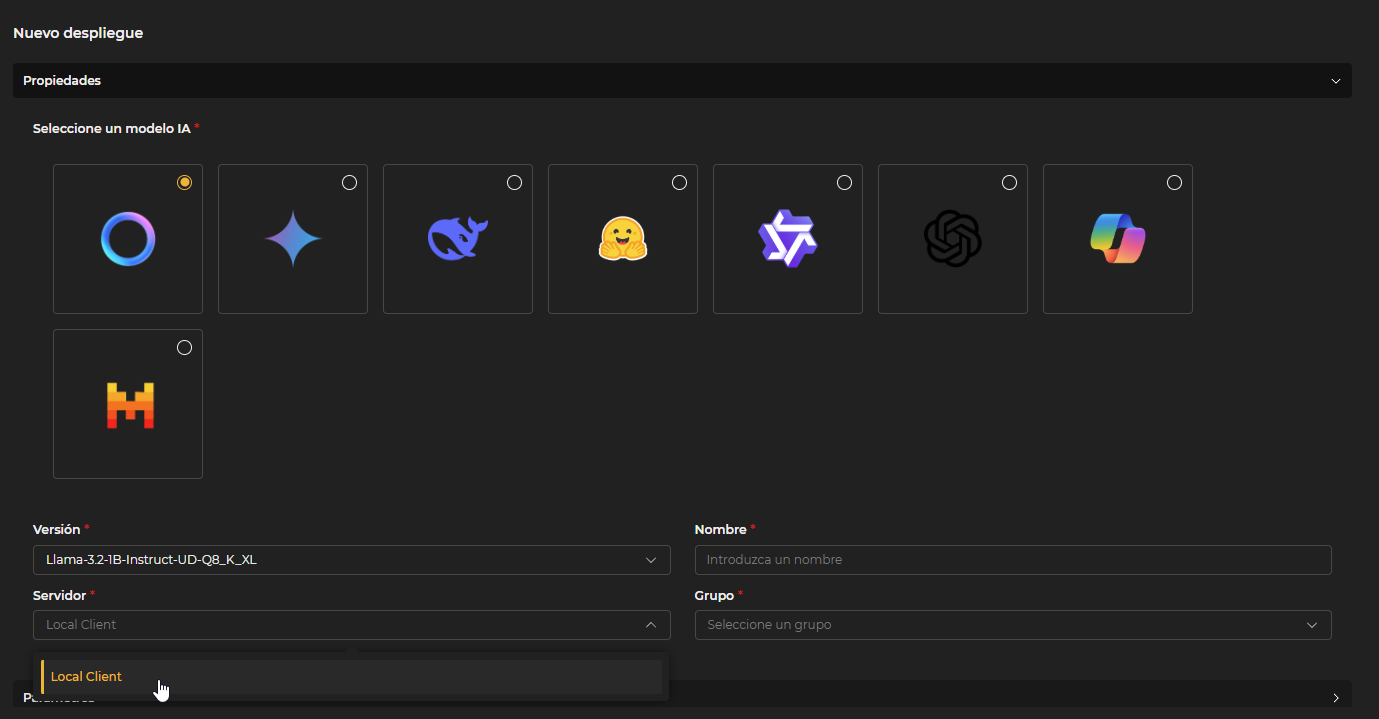 Figura 11.6: Propiedades de Despliegue
Figura 11.6: Propiedades de Despliegue
En los parámetros se introduce la API Key y se selecciona el Hardware que se va a utilizar para ejecutar el modelo (CPU o GPU).
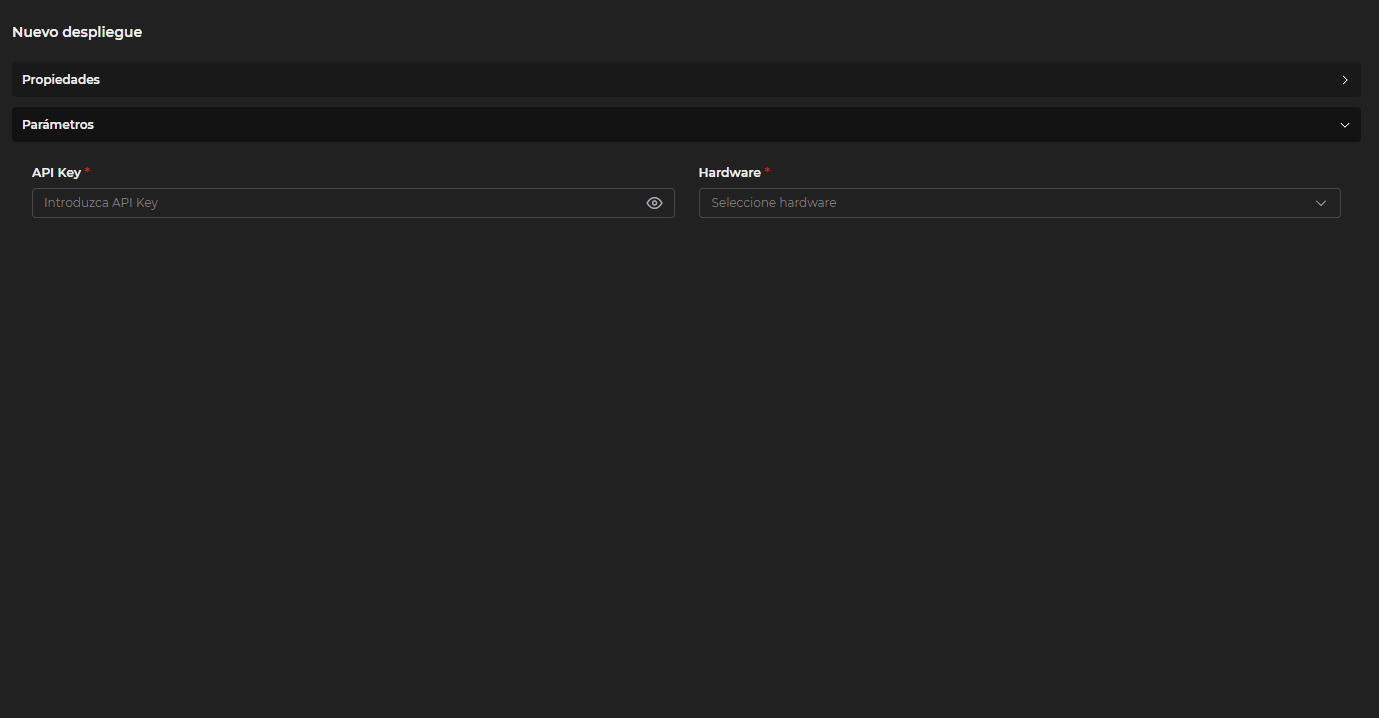 Figura 11.7: Parámetros de Despliegue
Figura 11.7: Parámetros de Despliegue
La pestaña Despliegues mantiene un formulario de añadir simplificado porque la configuración del modelo se añade en el botón Conectar, que da acceso a un formulario similar al de Público y Privado. En Reiniciar se lanza el proceso de parar e iniciar el modelo en cuestión. Una vez desplegados, aparecen en la pestaña Privado donde se pueden configurar como expertos.
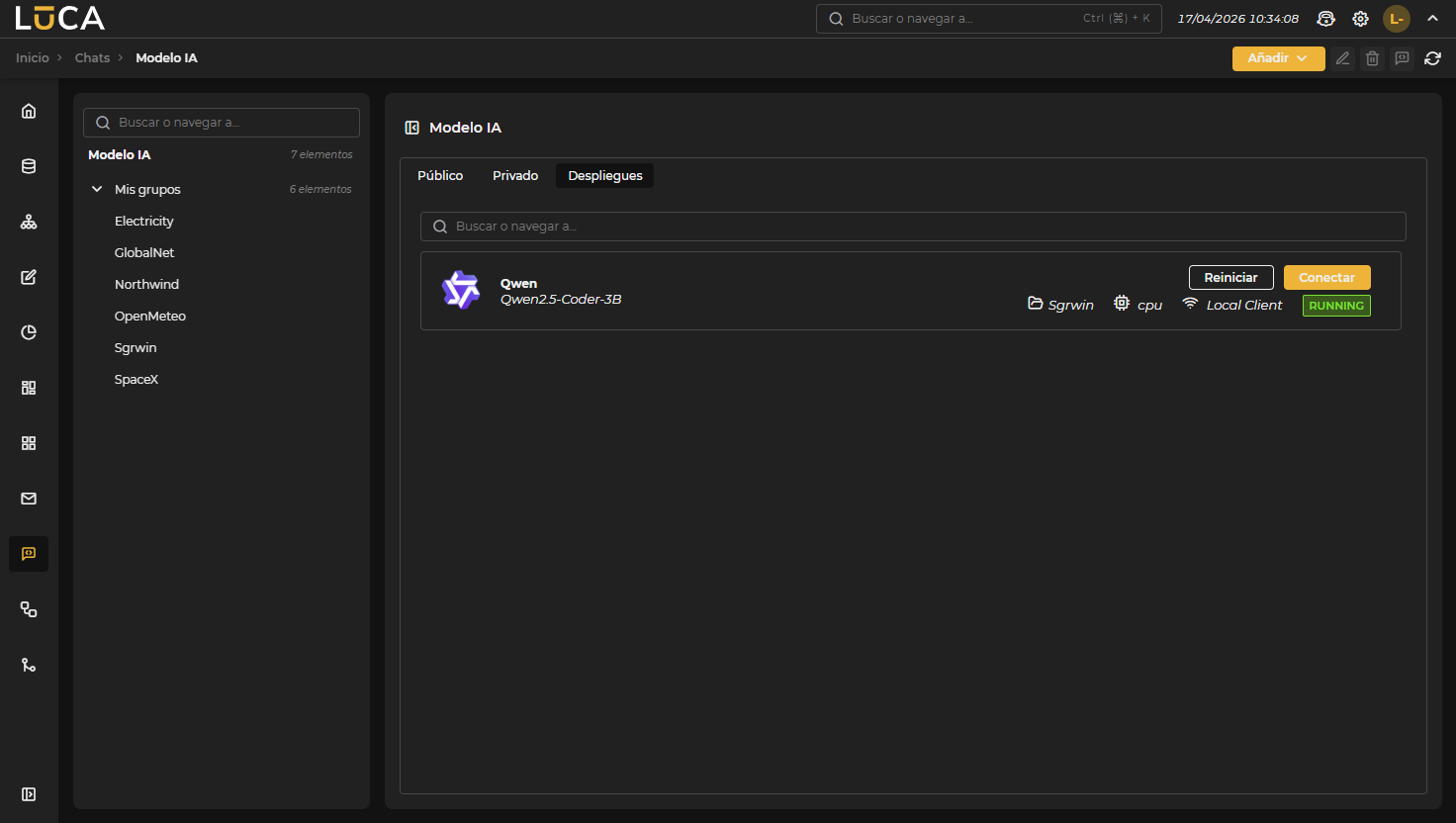 Figura 11.8: Conectar y Reiniciar
Figura 11.8: Conectar y Reiniciar

Figura 11.9: Botón editar
- Editar: Modifica la configuración del modelo resaltado.

Figura 11.10: Botón borrar
- Borrar: Elimina el modelo seleccionado.

Figura 11.11: Botón nuevo
- Nuevo Chat: Inicia una conversación (deshabilitado desde la pestaña despliegues) con el modelo elegido de la lista.

Figura 11.12: Botón recargar
- Recargar: Actualiza la lista de modelos.
Expertos SQL y LUCA
Además, en el caso de Público y Privado, se puede elegir si el modelo se convierte en predeterminado para algún tipo de consultas o chats, funcionando como experto. El sistema incorpora un selector de predeterminados que permite elegir entre los distintos modelos creados. En la sección de Modelos, tanto en la pestaña Público como en Privado, los selectores aparecen situados sobre las especificaciones de cada modelo. Para seleccionar un modelo como predeterminado es suficiente con activar el selector correspondiente. De este modo, las consultas dirigidas a expertos son atendidas por los modelos seleccionados.
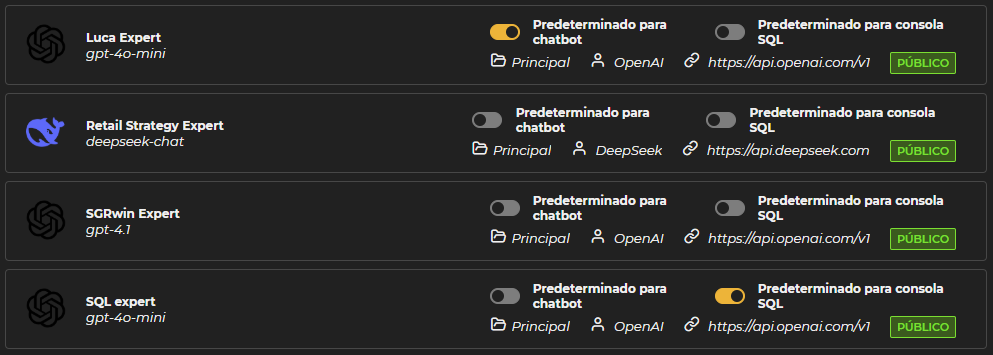 Figura 11.13: Expertos
Figura 11.13: Expertos
Tipos de expertos disponibles:
-
Experto SQL: El modelo marcado como experto SQL es el responsable de responder a las peticiones realizadas en el chat de la consola del apartado consultas.
-
Experto LUCA: El modelo seleccionado como experto LUCA atiende las consultas específicas relacionadas con la funcionalidad y uso de la plataforma LUCA, situado en la barra superior junto al icono del escritorio de aplicaciones.