3. Consultas
Las consultas son el mecanismo principal para extraer y gestionar información en LUCA. El resto de elementos —como gráficas, árboles u otros componentes visuales— se construyen a partir de estas.
Su flexibilidad y capacidad de parametrización las convierten en uno de los elementos clave de la configuración.
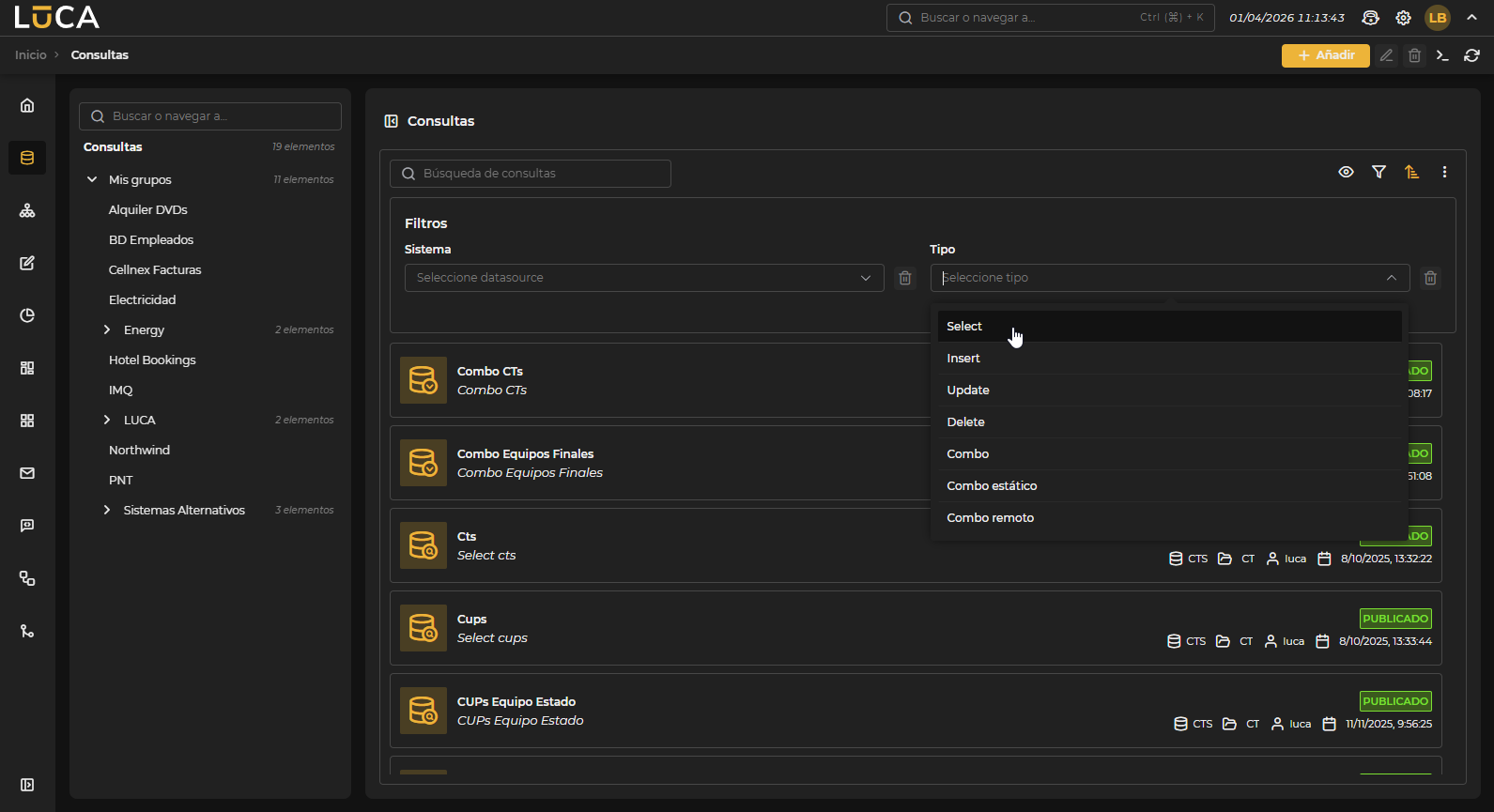 Figura 3.1: Administración de consultas
Figura 3.1: Administración de consultas
Para más información sobre la pantalla de administración general ver esta sección.
Creación y edición de consultas
En la vista de creación de consultas —cuyos elementos vienen por defecto colapsados, a excepción del editor— nos encontramos con la siguiente estructura:
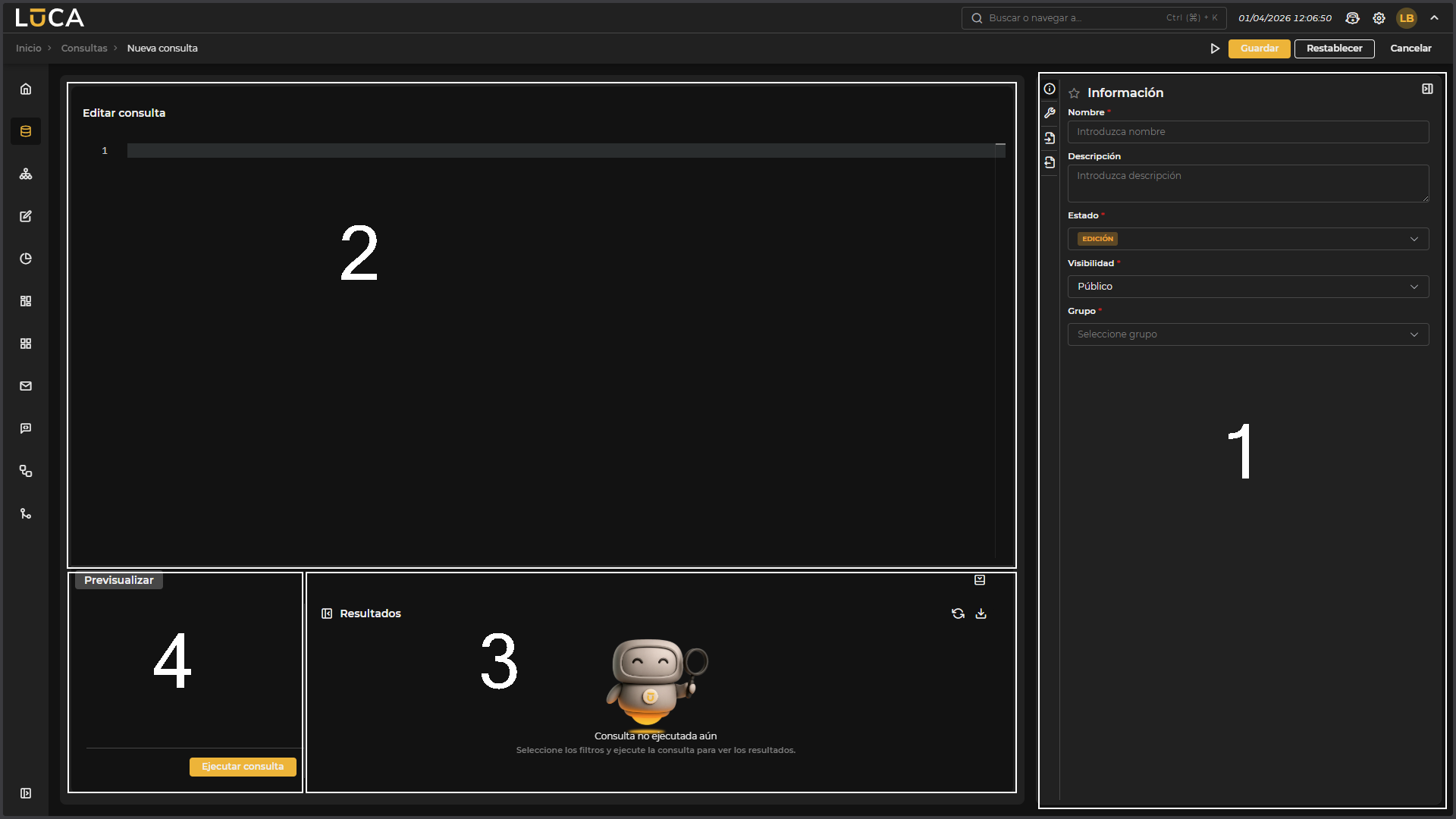 Figura 3.2: Creación de consultas
Figura 3.2: Creación de consultas
Configuración (1): Esta sección cuenta con cuatro menús en los que podremos configurar toda la información y parámetros de la consulta. Editor (2): Editor de texto que ofrece resaltado de sintaxis, facilitando la escritura y lectura de la consulta SQL. Resultados (3): Permite ejecutar la consulta y revisar sus resultados antes de guardarla. Previsualizar (4): Visible únicamente cuando el datasource de la consulta es de tipo Base de Datos. Permite consultar el esquema de la misma, incluyendo todas sus tablas y columnas.
Sobre el apartado de configuración, nos encontramos los siguientes botones:
- Ejecución: Guarda y ejecuta la consulta.
- Guardar: Guarda la información de la consulta.
- Restablecer: Borra los datos introducidos en el formulario.
- Cancelar: Cierra el editor y vuelve a la pantalla de administración de consultas.
Información
El formulario Información es común entre los elementos de LUCA.
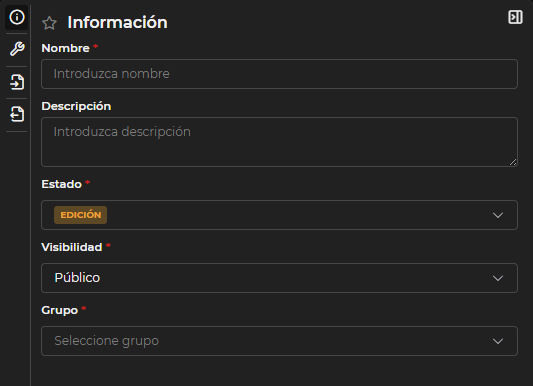
Figura 3.3: Formulario información
En LUCA, los elementos cuentan con un nombre y una descripción que facilitan su identificación, y siempre están asociados a un grupo, lo que permite gestionar el acceso de manera controlada.
Además, tienen un estado:
- Publicado: El elemento puede ser ejecutado y cualquier usuario —con los permisos necesarios— podrá hacer uso de él.
- En edición: Permite guardar el elemento mientras está en proceso de creación o modificación. Solo el usuario que lo está editando puede realizar cambios; el resto de usuarios no podrá ejecutarlo hasta que se publique.
Y una visibilidad —para gestionar quién puede ver el elemento—:
- Público: Los usuarios con acceso al grupo al que pertenece el elemento podrán interactuar con él, según los permisos asignados.
- Privado: Solo el usuario de creación y uno con permisos de administración pueden verlo.
- Pública restringida: Solo disponible en gráficas. Los usuarios no podrán utilizar filtros que no hayan sido predefinidos.
Configuración
Formulario específico de la consulta en el que se deben completar los siguientes campos.
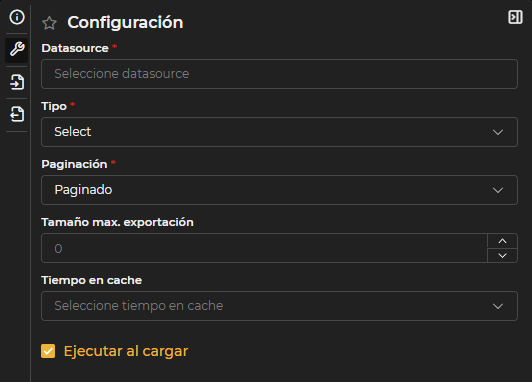
Figura 3.4: Formulario configuración de consultas
Datasource: Sistema de información en el que se va a ejecutar la consulta. Tipo de consulta
-
Select: Consulta de extracción de información.
-
Insert: Consulta para añadir uno o varios registros nuevos a una tabla de base de datos.
-
Delete: Consulta para borrar uno o varios registros de una tabla de base de datos.
-
Update: Consulta para actualizar uno o varios registros de una tabla de base de datos.
-
Combo: Consultas diseñadas para proporcionar una lista de opciones, cada una compuesta por un valor (interno) y un detalle (descriptivo), que pueden utilizarse en variables de entrada tipo combo.
-
Combo estático: Variante en la que la lista de opciones (valor y detalle) es fija y se define manualmente, ideal para desplegables sencillos como "Sí/No" o listas acotadas.
-
Combo remoto: Similar a las anteriores, pero la consulta que obtiene las opciones solo se ejecuta cuando el usuario comienza a filtrar por texto. Es especialmente útil para combos con muchos valores, ya que el número máximo de resultados está limitado por una paramétrica. Paginación
-
Paginado: Opción por defecto. Los resultados se muestran en páginas, lo que facilita la gestión de grandes volúmenes de datos y mejora el rendimiento. Es la alternativa más recomendable para consultas que pueden devolver muchos registros.
-
Paginado sin conteo: Similar al anterior, pero omite la consulta adicional que calcula el número total de registros. Es útil cuando el conteo resulta costoso y solo se necesita navegar por los datos página a página.
-
Sin paginar: Recupera Los resultados de una sola vez. Solo se aconseja para consultas que devuelven pocos datos, ya que puede afectar negativamente al rendimiento si el volumen es elevado.
Tamaño máximo de exportación: Establece el número máximo de registros que se exportarán a csv o Excel. Si aquí se indica un valor, este tendrá prioridad sobre el límite general definido en la paramétrica del sistema. Tiempo en caché: Permite almacenar temporalmente en memoria los resultados de la consulta, evitando su ejecución repetida mientras el tiempo configurado no haya expirado. Una vez transcurrido ese periodo, al volver a ejecutar la consulta, los datos se actualizarán y se almacenarán de nuevo en caché. Ejecutar al cargar: Si se activa esta opción, la consulta se ejecutará automáticamente al abrirla, aplicando los filtros de las variables de entrada que tengan valores predefinidos. Si alguna variable obligatoria no tiene valor por defecto, la consulta no se ejecutará ni mostrará resultados hasta que se complete dicho valor.
Opciones específicas para Insert, Update y Delete
Las consultas de tipo Insert, Update y Delete disponen de campos adicionales de configuración:
Máximo filas afectadas: Número máximo de registros que pueden ser modificados en una sola ejecución. Actúa como medida de seguridad para evitar modificaciones masivas no deseadas. Carga masiva: Permite cargar datos desde un archivo CSV para realizar inserciones o actualizaciones en bloque. Saltar primera línea: Al activarse, ignora la primera línea del archivo CSV, útil cuando esta contiene los nombres de las columnas. Separador CSV: Carácter utilizado para separar los valores en el archivo CSV (por defecto, coma). Tipo de confirmación: Define el comportamiento en caso de error durante la ejecución:
- Deshacer si falla: Revierte todos los cambios si ocurre algún error.
- Confirmar aunque falle: Aplica los cambios exitosos incluso si algunos registros fallan.
Variables de entrada
Las variables de entrada permiten al usuario filtrar los datos que devuelve la consulta según los criterios que defina. Por ejemplo, se puede introducir una fecha para obtener únicamente los registros posteriores a la misma.
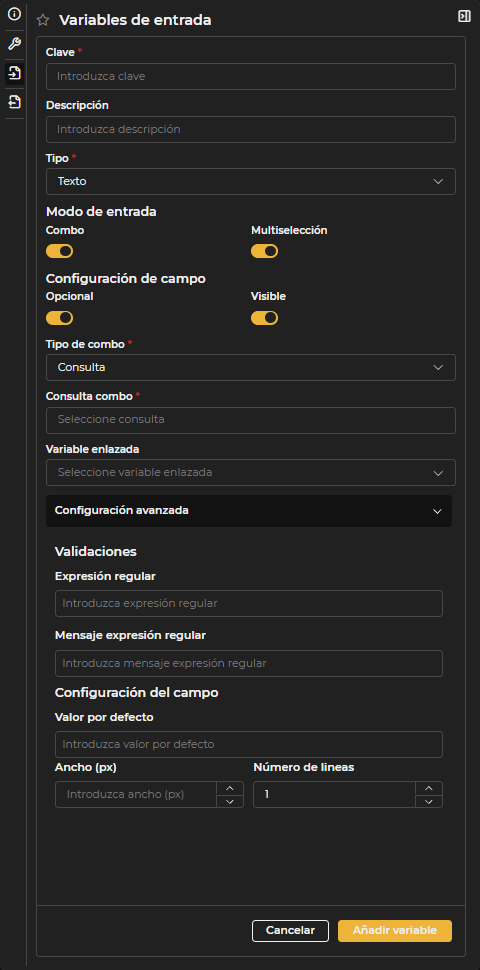
Figura 3.5: Formulario configuración variables de entrada
Clave: Identificador interno que se usará en el SQL. Debe estar formado solo por letras, números o guiones bajos, sin espacios ni caracteres especiales. Descripción: Etiqueta visible para los usuarios finales. Si no se indica, se mostrará la Clave como nombre descriptivo. Tipo
- Entero: Permite introducir solo números enteros.
- Decimal: Permite introducir números decimales.
- Texto: Permite introducir cadenas de texto.
- Boolean: Permite seleccionar entre dos valores: true (cuando está marcada) o false (cuando no lo está).
- Fecha: Permite seleccionar o introducir una fecha.
- Rango temporal: Permite seleccionar un intervalo de fechas, ya sea entre los rangos predefinidos o creando uno personalizado (ver valor personalizado).
Formato: Cuando la variable de entrada es numérica o de tipo fecha, es posible personalizar su formato. En variables numéricas, se puede indicar si se muestra el separador de miles y si se abrevian los valores (K, M, etc.). En el caso de variables decimales, se permite definir el número mínimo y máximo de decimales. Para variables de tipo fecha, existen varias opciones de formato disponibles. Multiselección: Permite seleccionar más de un valor. Cuando la opción Combo está habilitada, se muestra un desplegable con un botón para seleccionar o deseleccionar todos los valores de una vez. Cuando Combo está deshabilitado, el usuario introduce los valores uno a uno y los va agregando al selector. Opcional: Indica si la variable de entrada es opcional o si requiere un valor obligatorio para ejecutar la consulta. Visible: Determina si la variable de entrada será visible para el usuario. Por ejemplo, puede resultar útil ocultar variables de tipo Usuario actual. Configuración avanzada: Permite definir opciones adicionales para cada variable, como validación mediante expresiones regulares, valores mínimos y máximos para entradas numéricas, valores por defecto y el ancho en píxeles de la variable.
Una vez completada la configuración, se debe seleccionar la opción de añadir o confirmar variable para aplicar los cambios.
En consultas de tipo Insert o Update, las variables de entrada conforman el formulario necesario para crear o editar el registro correspondiente.
Los cambios realizados en las variables de entrada no se guardan automáticamente. Es necesario persistir la consulta para confirmar los cambios.
Variables de salida
Las variables de salida deben declararse cuando se utilizan en una gráfica, en otros elementos de LUCA o cuando se requiere modificar el formato de una columna. Por ejemplo, si la consulta devuelve una fecha, es posible definir el formato de visualización o asignar una descripción diferente a la definida en el SQL.
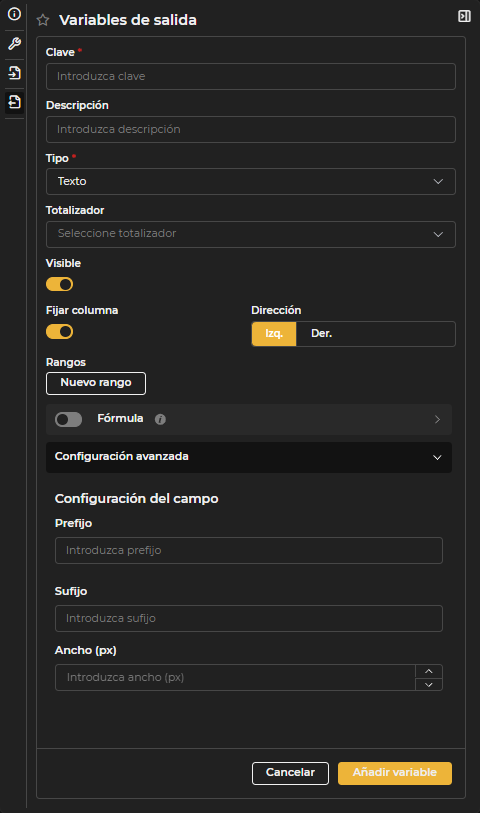
Figura 3.6: Formulario configuración variables de salida
Clave: Nombre de la columna tal como aparece en el SQL. Descripción: Nombre de la variable que será visible para los usuarios finales. En el caso de que no se defina una descripción se usará la Clave como descripción. Tipo
- Entero: Devuelve solo números enteros.
- Decimal: Devuelve números decimales.
- Texto: Devuelve cadenas de texto.
- Fecha: Devuelve fechas. Permite definir el formato de visualización (por ejemplo, dd/MM/yyyy, dd/MM/yyyy HH:mm).
- URL: Devuelve enlaces o direcciones URL.
- Latitud-Longitud: Devuelve un punto geográfico en formato LATITUD,LONGITUD (por ejemplo: 40.714123,-74.006231).
Totalizador: Permite mostrar un total al final de la tabla para la columna seleccionada.
- Conteo: Muestra el número total de resultados.
- Distintos: Muestra el número de resultados distintos.
- Suma: Muestra la suma de los valores.
- Media: Muestra el promedio de los valores.
- Mínimo: Muestra el valor mínimo.
- Máximo: Muestra el valor máximo.
Visible: Determina si la variable de salida será visible para el usuario. Puede ser útil ocultar variables que se usan como enlace o identificador, pero no se muestran en la tabla. Fijar columna: Permite fijar la columna en el lado seleccionado de la tabla, para que permanezca visible aunque haya muchas columnas. Rangos: Permite resaltar valores con colores según rangos definidos. Se pueden configurar varios rangos para una misma variable.
- Color: Color aplicado al rango.
- Color del texto: Color del texto si el tipo elegido es Fondo.
- Tipo: Texto aplica color al texto; Fondo aplica color al fondo de la celda.
- Modo: Celda aplica el color solo a la celda; Fila aplica el color a toda la fila.
- Condiciones: Permite definir condiciones para aplicar el color. Por ejemplo, si el valor es igual a OK se aplica verde; si está entre 50 y 100 se aplica rojo.
Fórmula: Permite crear variables calculadas a partir de otras variables de salida. Las variables se indican entre corchetes y se pueden usar operaciones simples, por ejemplo:
[NAME] ` ' ' ` [SURNAME][TIME_SECONDS] / 60
Configuración avanzada
- Prefijo: Añade un texto como prefijo a los valores de la columna.
- Sufijo: Añade un texto como sufijo a los valores de la columna.
- Ancho: Define el ancho en píxeles de la columna de salida.
Una vez configurada la variable, seleccionar Añadir variable o Confirmar variable para aplicar los cambios.
Solo es necesario declarar las columnas que se vayan a usar en otros elementos de LUCA o a las que se quiera aplicar un formato.
Variables internas
Además de las variables de entrada configuradas en cada consulta, LUCA expone tres variables internas siempre disponibles:
:LUCA_CURRENT_USER: identifica al usuario autenticado.:LUCA_CURRENT_DATE: devuelve la fecha y hora de ejecución.:LUCA_ENV: indica el entorno activo.
Se pueden referenciar directamente en el SQL o en el código Velocity sin necesidad de declararlas previamente ni asignar valores por defecto.
Editor de consultas
En la parte central se encuentra el editor de consultas donde se puede escribir el código SQL a ejecutar.
Debajo del editor se encuentra el apartado de previsualización, accesible haciendo clic sobre el texto Previsualizar. Esta sección permite probar la ejecución de la consulta, mostrando las variables de entrada configuradas para introducir valores de prueba y evaluar los distintos comportamientos de la consulta.
Además del SQL, se puede añadir código Velocity a las consultas. El uso principal de Velocity en LUCA es permitir que las variables de entrada sean opcionales, aunque también se puede utilizar para otros casos.
Para utilizar una variable de entrada en el SQL se debe añadir con el formato :CLAVE. El siguiente ejemplo supone que existe una variable de entrada cuya clave es USERNAME.
select * from luca_execution_register
where username = :USERNAME
Para hacer que la variable USERNAME sea opcional, se debe utilizar Velocity. La directiva #if($USERNAME) ... #end comprueba si se ha introducido algún valor en la variable de entrada. Si existe algún valor, se añadirá a la consulta todo el código incluido entre #if ... #end.
select * from luca_execution_register
where 1=1
#if($USERNAME)
and username = :USERNAME
#end
Las variables en el SQL se deben utilizar con el formato :CLAVE, mientras que en el código Velocity se utiliza el formato $CLAVE.
Si la variable de entrada USERNAME ha sido marcada como multiselección, se debe usar in \#USERNAME# en lugar de = :USERNAME.
select * from luca_execution_register
where 1=1
#if($USERNAME)
and username in #USERNAME#
#end
La directiva \#USERNAME# se reemplaza durante la ejecución por (SELECT 'username1' USERNAME UNION ALL SELECT 'username2' UNION ALL ...), lo que permite utilizarla de la siguiente manera.
select *
from luca_execution_register ER
inner join #USERNAME# U ON ER.username = U.USERNAME
Los ejemplos anteriores muestran el uso de una sola variable de entrada, pero se puede incluir tanto código Velocity como sea necesario.
select * from luca_execution_register
where 1=1
#if($VARIABLE1)
and columna1 = :VARIABLE1
#end
#if($VARIABLE2)
and columna2 = :VARIABLE2
#end
También se puede utilizar la cláusula #if ... #elseif ... #end.
select * from luca_execution_register
where 1=1
#if($VARIABLE1)
and columna1 = :VARIABLE1
#elseif($VARIABLE2)
and columna2 = :VARIABLE2
#end
Para variables de entrada de tipo rango temporal cuya clase sea DATE_RANGE, se puede acceder a sus valores anteponiendo el símbolo $ a la clave, seguido de un punto y el valor deseado. Los valores disponibles son:
dateFrom: fecha inicial del rango.dateTo: fecha final del rango.prevDateFrom: fecha inicial del periodo anterior al rango actual.prevDateTo: fecha final del periodo anterior al rango actual.
A continuación se muestra un ejemplo de uso:
select
case
when execution_date >= $DATE_RANGE.dateFrom then 'current'
else 'previous'
end period,
*
from executions
where execution_date
between $DATE_RANGE.prevDateFrom and $DATE_RANGE.dateTo
Es importante tener en cuenta que el valor de la variable se devuelve en formato string, por lo que es necesario utilizarlo entre comillas y convertirlo a fecha. La conversión se realiza de forma distinta según el tipo de base de datos. El formato de fecha es dd/MM/yyyy HH:mm:ss. A continuación se muestran ejemplos de conversión para diferentes bases de datos:
Tabla 3.1: Sintaxis conversión texto a fecha
| Base de datos | Sintaxis |
|---|---|
| MariaDB/MySQL | STR_TO_DATE('$DATE_RANGE.dateFrom', '%d/%m/%Y %H:%i:%s') |
| PostgreSQL | TO_DATE('$DATE_RANGE.dateFrom', 'DD/MM/YYYY HH:MI:SS') |
| SQLServer | CONVERT(varchar,'$DATE_RANGE.dateFrom',131) |
| Oracle | TO_DATE('$DATE_RANGE.dateFrom', 'DD/MM/YYYY HH24:MI:SS') |
| Neo4j | datetime('$DATE_RANGE.dateFrom') [small]#Formato requerido: 'yyyy-MM-ddTHH:mm:ss'# |
La sintaxis en Trino es muy similar a la de la base de datos que utilice, aunque con pequeñas variaciones. En caso de duda, consulte el manual de Trino disponible link:aquí.
Las variables de tipo boolean se pueden utilizar como cualquier otra variable en Velocity, lo que permite filtrar columnas que no estén definidas como boolean. A continuación se muestra un ejemplo con una variable de tipo boolean con clave IS_FINISHED:
select *
from tickets
where date_end #if($IS_FINISHED) is not null
#else is null #end
Ejecución de consultas
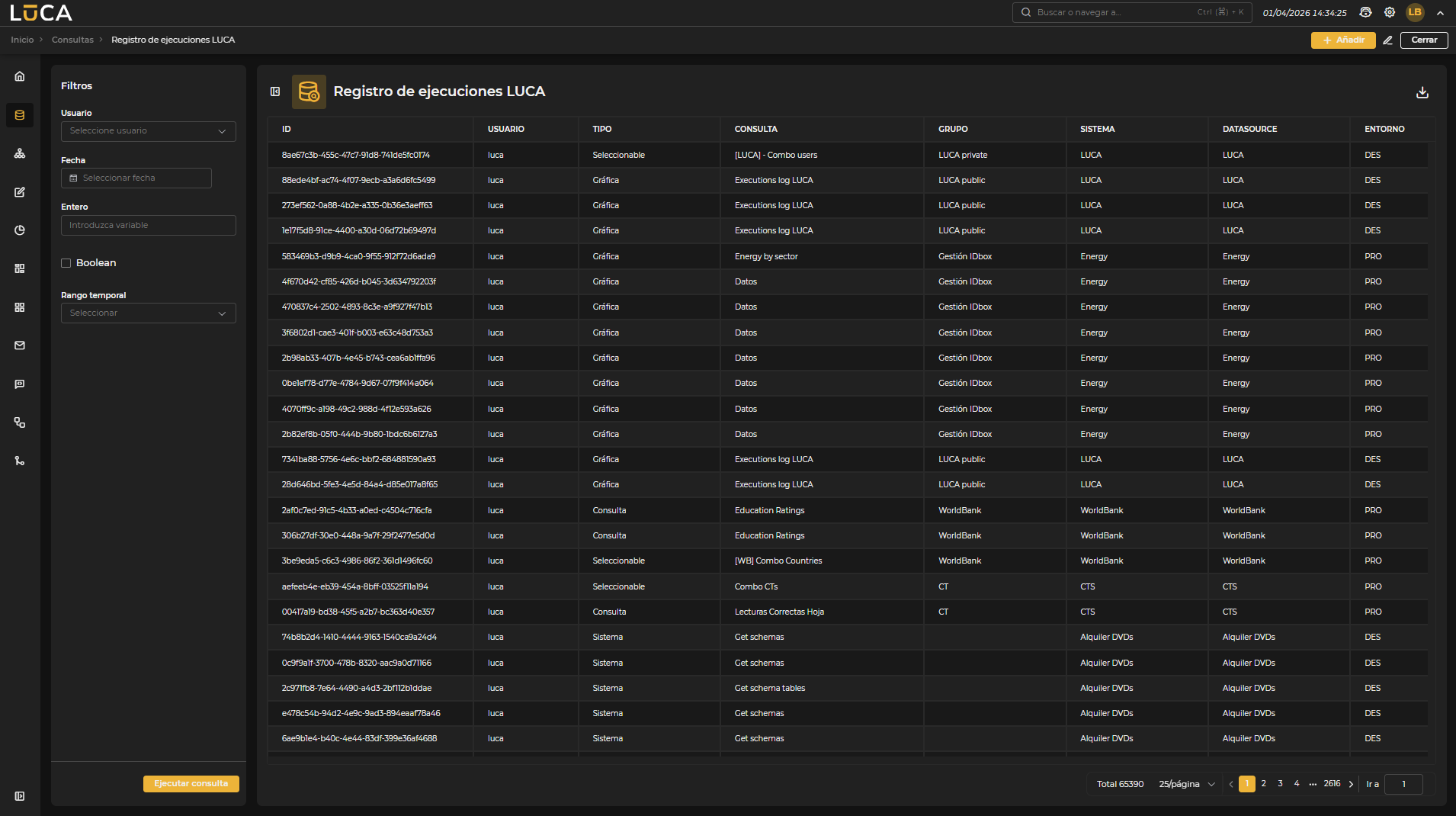 Figura 3.7: Ejecución de consultas
Figura 3.7: Ejecución de consultas
La vista de ejecución permite visualizar los resultados de la consulta. En la parte izquierda se muestran las variables de entrada para filtrar los datos y el selector de entorno donde se ejecutará la consulta. Para iniciar la ejecución, se debe hacer clic en el botón Ejecutar consulta.
En la parte superior derecha se dispone de los botones Añadir, Editar, Exportar y Cerrar. El botón Exportar permite generar un archivo CSV o Excel con los resultados de la consulta.
Consultas Combo
Las consultas de tipo Combo, Combo estático y Combo remoto están diseñadas para proporcionar valores a variables de entrada de tipo combo.
Estas consultas requieren la declaración de dos variables de salida obligatorias:
- DETALLE: Texto que se mostrará al usuario en el desplegable.
- VALOR: Valor interno utilizado para el filtrado. Puede diferir del detalle mostrado. Por ejemplo, en un selector de tipos, la variable VALOR puede ser un identificador numérico mientras que DETALLE contiene la descripción textual.
Estas variables se crean automáticamente al seleccionar una consulta de tipo combo.
Combo
Además de las variables de salida obligatorias, las consultas de tipo Combo admiten una única variable de entrada adicional. Esta variable puede tener cualquier clave y se utiliza para enlazar una variable de tipo combo con otra.
Si se declaran múltiples variables de entrada, solo se utilizará la primera para el enlace; el resto se ignorarán.
Combo remoto
Este tipo de consultas requiere una variable de entrada con la clave SEARCH. Esta variable se utiliza en el SQL para filtrar los resultados según el texto introducido por el usuario en el desplegable. Ejemplo:
SELECT USERNAME AS DETALLE, USERNAME AS VALOR
FROM USERS
WHERE 1=1
#if($SEARCH)
AND USERNAME LIKE '%:SEARCH%'
#end
Además de la variable SEARCH, se puede declarar una variable de entrada adicional para crear un combo remoto enlazado, tal como se describe en el apartado anterior.
Combo estático
A diferencia de los tipos anteriores, los combos estáticos definen valores fijos que no se obtienen mediante la ejecución de una consulta. Este tipo es apropiado cuando el conjunto de opciones es reducido y estable en el tiempo.
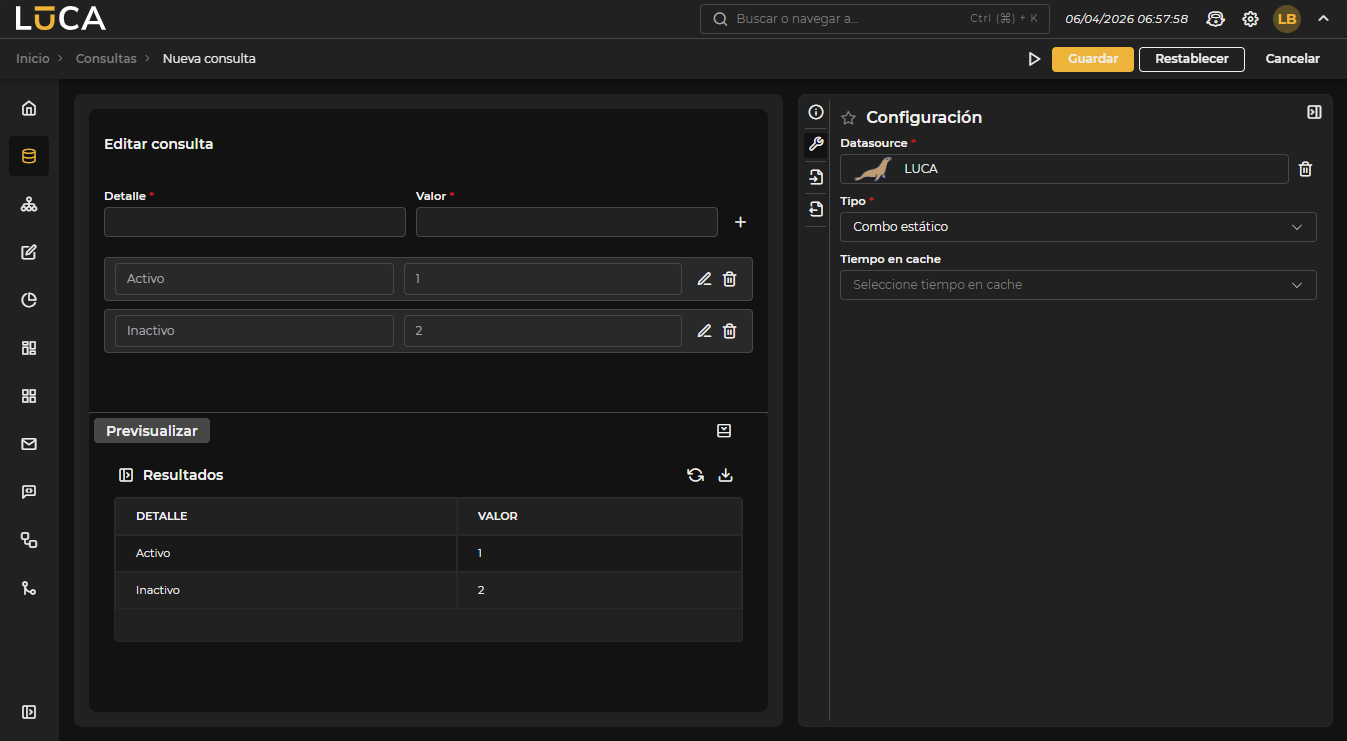 Figura 3.8: Consulta Combo estático
Figura 3.8: Consulta Combo estático
Consultas Http
LUCA también permite realizar consultas a servicios web API REST o SOAP.
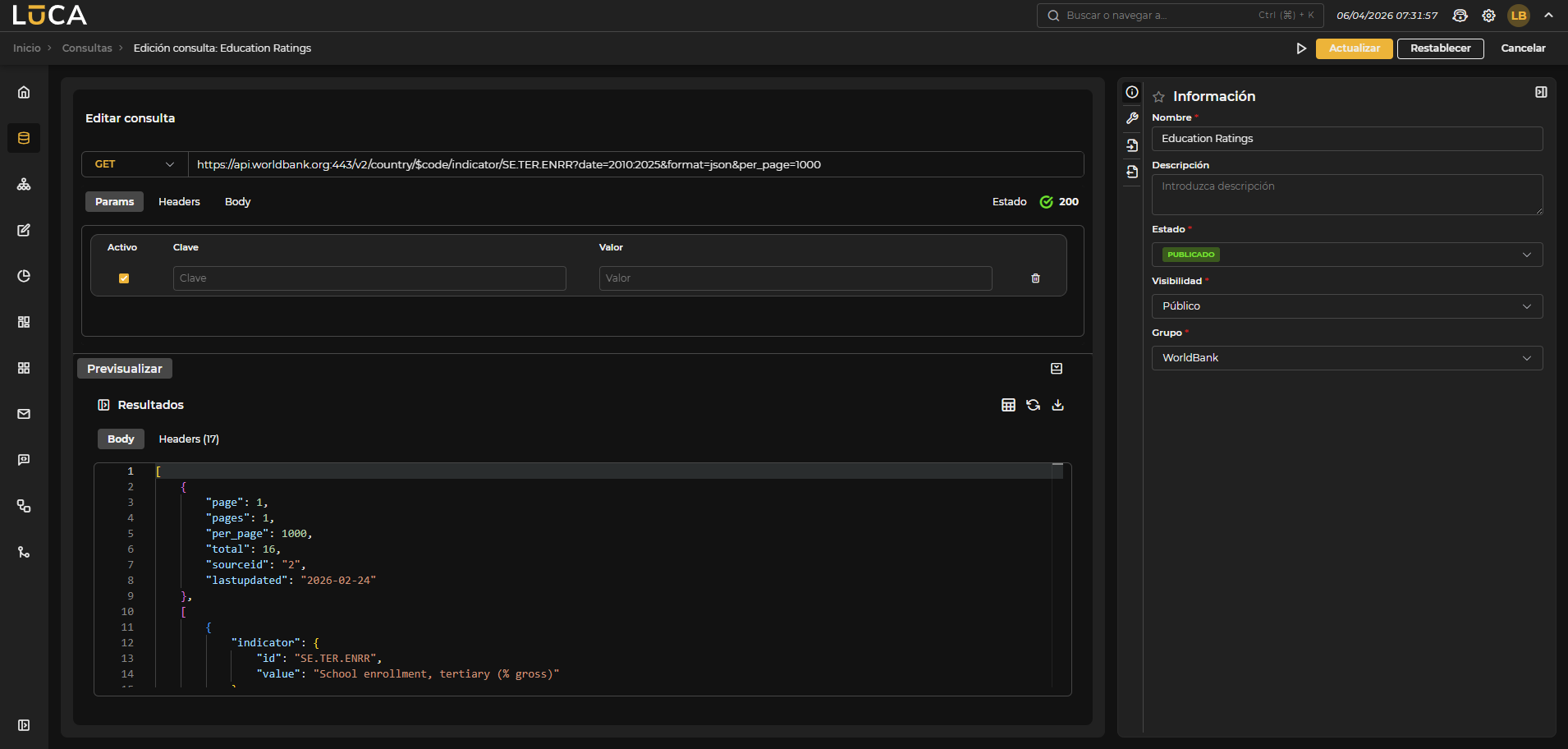 Figura 3.9: Consulta Http
Figura 3.9: Consulta Http
Configuración
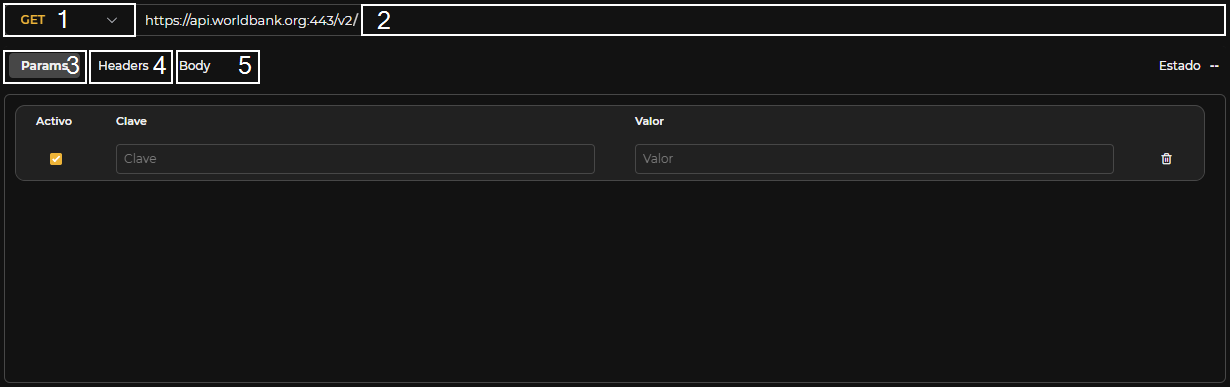 Figura 3.10: Configuración Http
Figura 3.10: Configuración Http
En las consultas a datasources de tipo Http se pueden configurar los siguientes campos:
-
Método: GET, POST, PUT o DELETE
-
Path a añadir a la petición a partir del dominio configurado en el Datasource. En el path se pueden utilizar variables de Velocity para, por ejemplo, utilizar una variable de entrada como:
https://www.example.com/users/$user
- Parámetros que se concatenarán a la URL como:
?param1=value1¶m2=value2
Los valores de los parámetros se escapan de forma automática, por lo que no es necesario introducir el valor escapado previamente.
Es posible utilizar código Velocity en los valores de los parámetros para utilizar variables de entrada previamente creadas. Para valores muy largos o que requieran código Velocity, existe la posibilidad de editar el valor en un editor de texto. En la parte superior de este editor se muestran las variables de entrada previamente declaradas. Los botones superiores permiten añadir la variable deseada al editor pulsando sobre el botón correspondiente.
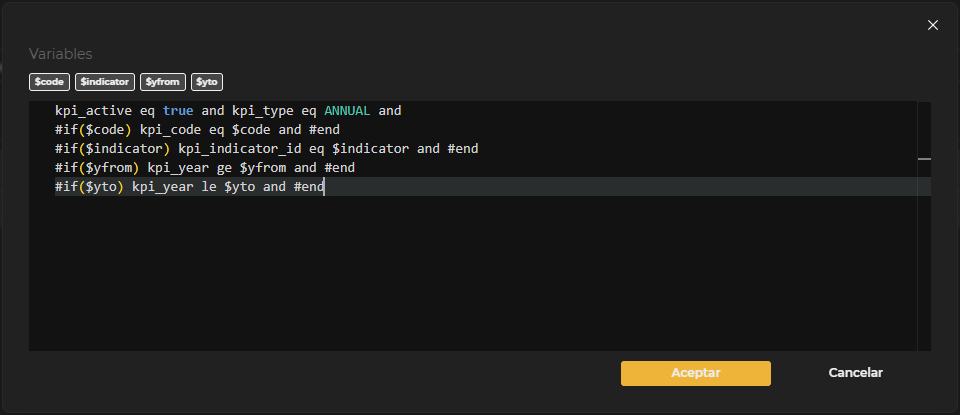 Figura 3.11: Edición parámetro Http
Figura 3.11: Edición parámetro Http
También se puede definir un parámetro opcional utilizando Velocity de la siguiente manera:
| Clave | Valor |
|---|---|
| sortBy | $if($sortBy)$sortBy#end |
En el caso de que no se rellene la variable de entrada sortBy el valor del parámetro estará vacío y no se añadirá a la URL.
-
Headers que puede necesitar la petición. Poseen las mismas opciones de configuración que los parámetros.
-
Body. En el caso de que la petición necesite un body, se podrá configurar uno de tipo 'x-www-form-urlenconded' o 'application/json'.
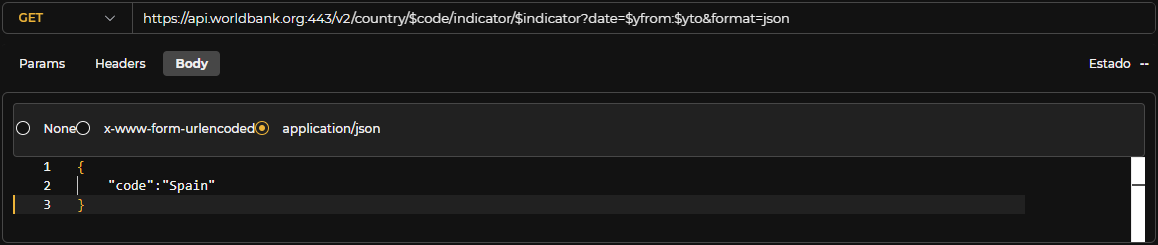 Figura 3.12: Edición body Http
Figura 3.12: Edición body Http
Existen las variables de entrada $pageSize y $pageNumber que se pueden utilizar en cualquier apartado de la configuración de la consulta para realizar un paginado.
Estas variables están declaradas por defecto y se rellenan con los valores que contiene el paginador de la tabla. Para ello es necesario marcar la consulta como paginada.
Consultas LOG
LUCA dispone de un conector a ficheros de log publicados por http/s. Este conector permite realizar búsquedas por fecha o navegar por el fichero de forma paginada.
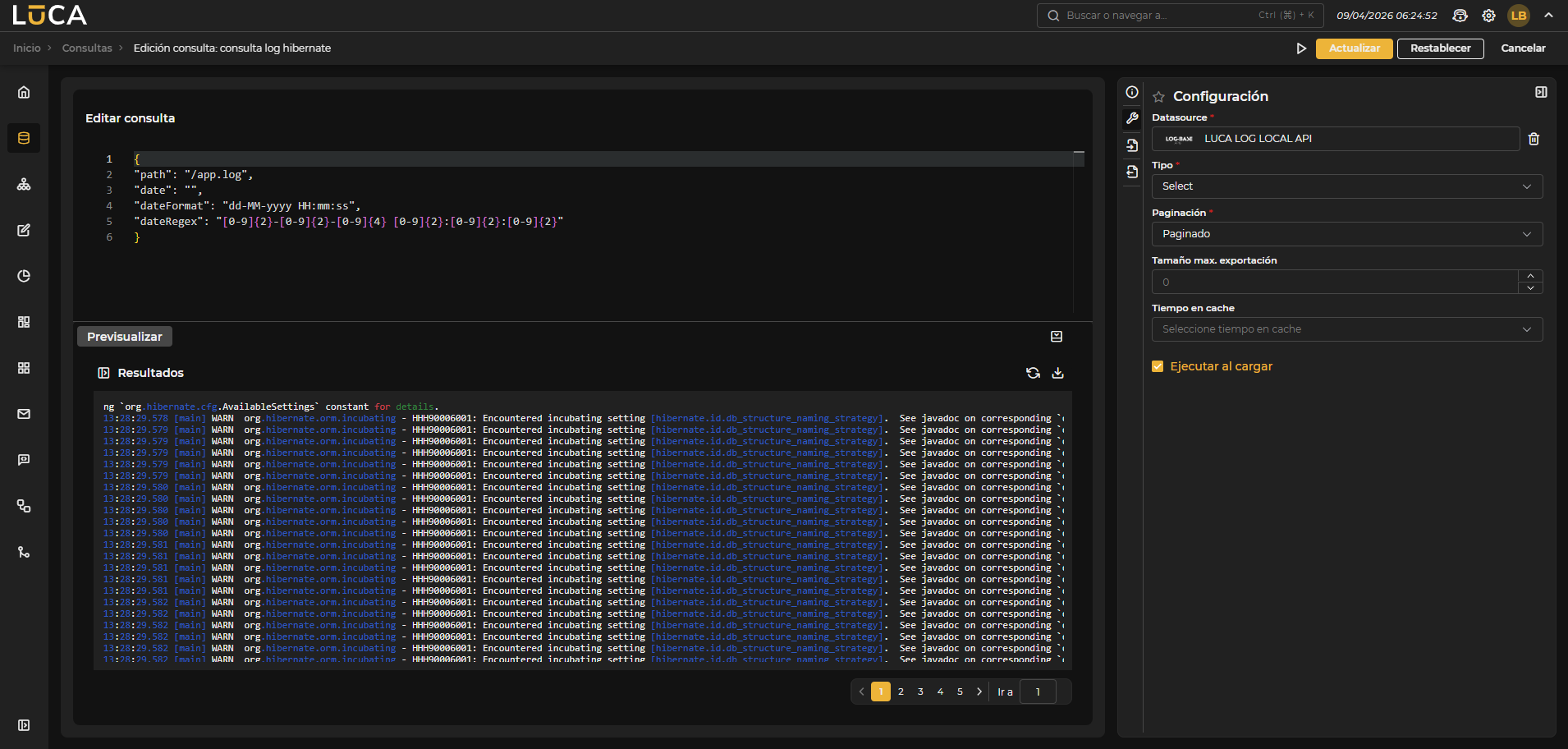 Figura 3.13: Consulta LOG
Figura 3.13: Consulta LOG
Configuración
A diferencia de las consultas de base de datos en las que se escribe código SQL, para el conector de LOG se debe definir un JSON con un formato específico para su correcto funcionamiento.
{
"path": string,
"headers": Map<string, string>,
"date": string,
"dateFormat": string,
"dateRegex": string
}
- path: Ruta del fichero de log al que se desea acceder.
- headers: Cabeceras HTTP adicionales que se pueden incluir en la petición. Opcional.
- date: Fecha a buscar en el log. Parámetro opcional si no se requiere búsqueda por fecha.
- dateFormat: Formato de fecha de link:Java que define cómo se formatea la fecha a buscar. Opcional si no se requiere búsqueda por fecha.
- dateRegex: Expresión regular que define el patrón de la fecha a buscar. Opcional si no se requiere búsqueda por fecha.
En este ejemplo se supone un log publicado en www.example.com/logs/app.log y un Datasource de tipo LOG declarado con el dominio www.example.com.
{
"path": "/app.log",
"date": "",
"dateFormat": "dd-MM-yyyy HH:mm:ss",
"dateRegex": "[0-9]{2}-[0-9]{2}-[0-9]{4} [0-9]{2}:[0-9]{2}:[0-9]{2}"
}
Dentro del JSON se puede seguir utilizando código Velocity para referenciar variables de entrada o realizar cálculos.
Consola SQL
La consola SQL permite ejecutar consultas directamente sobre la base de datos sin necesidad de crear y configurar una consulta, aunque esta no se guardará. Para acceder se debe ir a la pestaña de consultas y hacer clic en el icono de la consola SQL.

Figura 3.14: Icono consola SQL
En la parte izquierda se debe seleccionar el datasource y el entorno sobre los que se ejecutará la consulta. Una vez seleccionados, se muestra el árbol de la base de datos. Al hacer doble clic sobre cualquier database, tabla o columna, se inserta automáticamente en el editor.
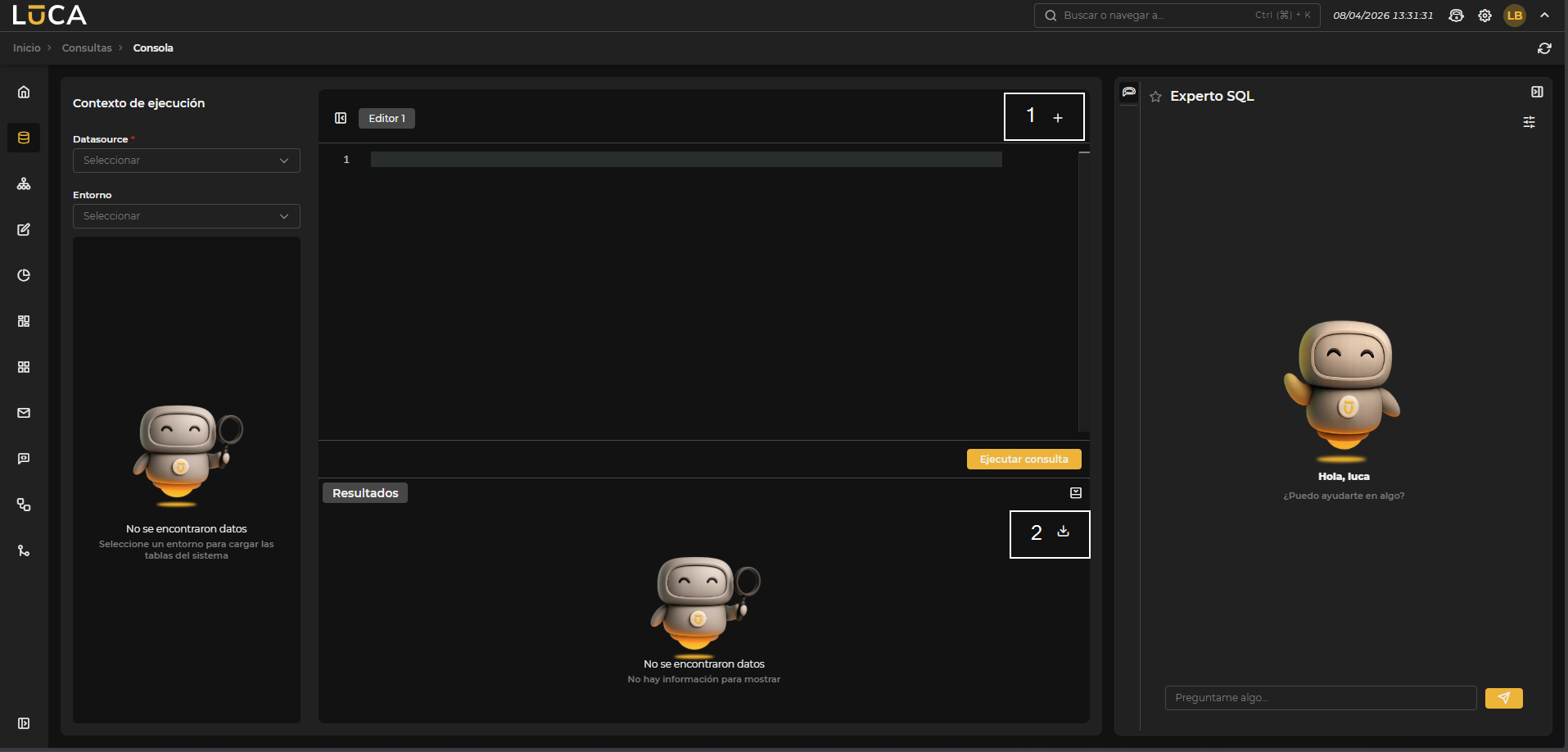 Figura 3.15: Página principal
Figura 3.15: Página principal
En la parte central se encuentra el editor donde se puede escribir la consulta. Se pueden crear varios editores para gestionar diferentes consultas mediante el botón (1) situado en la parte superior derecha. Debajo del editor se encuentran el botón de Ejecutar consulta y la vista previa de la ejecución de la consulta al desplegar Resultados. Además, en el lateral derecho, disponemos de un botón (2) con opciones para exportar los datos de la ejecución de la consulta a CSV o Excel.
En el lateral derecho de la pantalla se encuentra el panel del Experto SQL, que puede desplegarse o contraerse. Este panel ofrece un chat de inteligencia artificial especializado en SQL que asiste al usuario en la escritura de consultas. Antes de iniciar la conversación es posible configurar:
Modelo IA: Modelo de IA que actuará como experto. El modelo marcado como Experto SQL en la configuración de Modelos será el que aparezca por defecto. Esquema: Esquema de la base de datos sobre el que el experto contextualizará sus respuestas. Al seleccionarlo, el modelo tendrá en cuenta la estructura de tablas y columnas de ese esquema.
Una vez configurado, se puede pulsar Aplicar para confirmar los cambios o Limpiar para reiniciar la conversación.
Nada de lo que se escriba en los editores se guardará al cerrar o cambiar de ventana. Esta información solo estará disponible mientras se permanezca en la consola SQL.